Build a Saga Orchestrator in Python - From Zero to Live Dashboard
Table of Contents
TL;DR: Distributed transactions don’t work across microservices. Sagas replace them with a sequence of local transactions and compensating actions for rollback. This post follows a single airline booking through a saga orchestrator - from reservation to confirmation - and shows what happens when a step fails. The companion repo runs the whole thing with a live dashboard.
What’s a Transaction, Really? #
Transfer 500 euros from checking to savings. Two operations: debit one account, credit the other. If the credit fails after the debit succeeds, money has vanished into thin air.
Databases solved this problem decades ago. Wrap both operations in a transaction - they either both commit or both roll back. All or nothing. We’ve been relying on this guarantee so long that most of us don’t think about it anymore.
Now split that bank into two services. Account Service owns one database. Ledger Service owns another. There’s no single transaction that can span both. The “all or nothing” guarantee just evaporated.
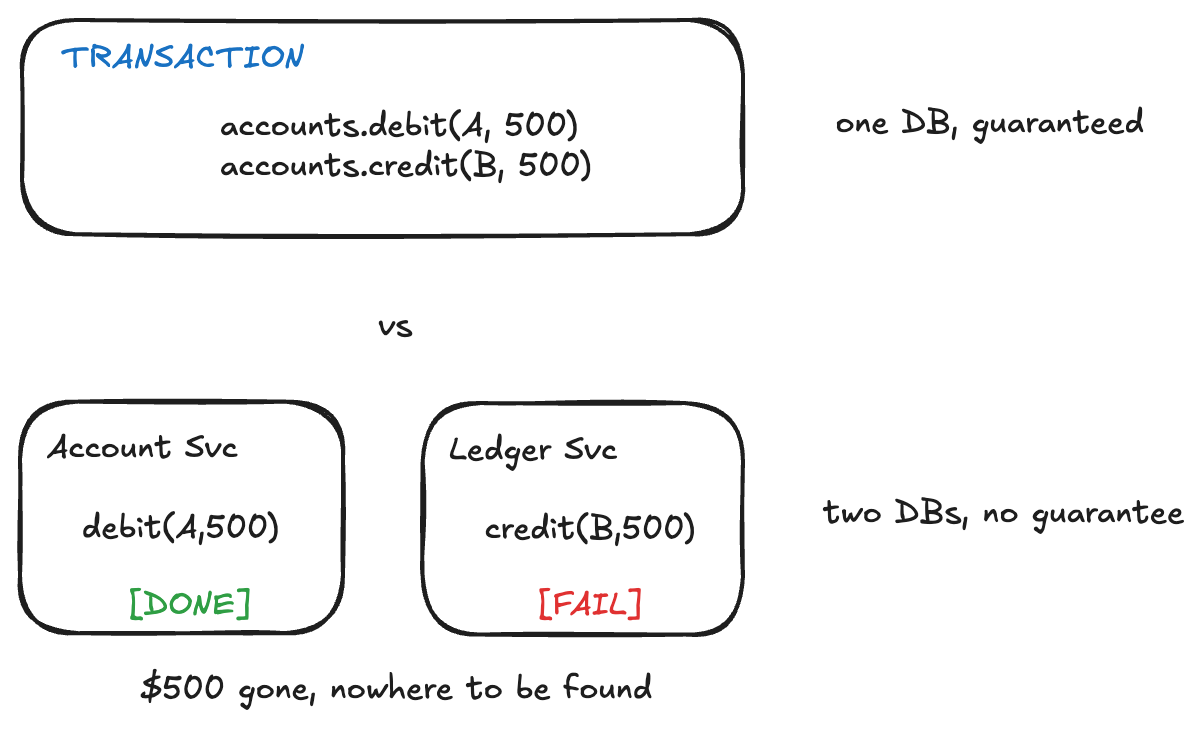
The airline version #
The same problem shows up anywhere multiple services need to agree. Take an airline booking that touches five systems:
- Inventory reserves seats
- Payment charges the card
- Check-in allocates a boarding slot
- Miles awards loyalty points
- Booking tracks the whole thing
Seats get reserved. Payment gets authorized. Then check-in says there are no slots available. Now what? The seats are locked, the card is charged, and the passenger has nothing.
You can’t roll back a committed transaction in another service’s database. You need to issue new actions that undo the effect. Release those seats. Void that payment. These are business operations, not database rollbacks.
The pattern has a name #
This is the saga pattern1. A sequence of local transactions where each step either succeeds and triggers the next, or fails and triggers compensating transactions in reverse order. No distributed locks, no two-phase commit, no coordinator that holds everything hostage.
Two-phase commit (2PC) exists, yes. It requires all participants to hold locks until the coordinator says “go.” That works when you have two databases in the same data center. It doesn’t work when you have five services that need to stay available independently.
In this project, I use a hybrid approach. Services react to events and publish outcomes (choreography), but the booking service tracks saga state centrally (orchestration). Pure choreography has no central tracker - every service just reacts. Pure orchestration has a coordinator issuing commands. This sits in between. The booking service knows which step the saga is on. It doesn’t tell services what to do; it listens for what they did and decides what’s next.
Best way to explain a pattern is to make it run. Here’s what I built.
The State Machine #
Every saga needs something tracking where it is. In this implementation, that’s a simple status enum on the booking record:
class BookingStatus(str, enum.Enum):
PENDING = "PENDING"
SEATS_RESERVING = "SEATS_RESERVING"
PAYMENT_AUTHORISING = "PAYMENT_AUTHORISING"
CHECKIN_ALLOCATING = "CHECKIN_ALLOCATING"
MILES_AWARDING = "MILES_AWARDING"
CONFIRMED = "CONFIRMED"
COMPENSATING = "COMPENSATING"
CANCELLED = "CANCELLED"
The happy path is linear:
PENDING -> SEATS_RESERVING -> PAYMENT_AUTHORISING -> CHECKIN_ALLOCATING -> MILES_AWARDING -> CONFIRMED
Each transition means: “the previous step succeeded, move to the next.” The orchestrator doesn’t execute any business logic itself - it reacts to events from other services and advances the state.
Here’s what that looks like in code (full handlers). When the inventory service publishes SeatsReserved, the booking service picks it up:
@broker.on_event(SeatsReserved)
async def on_seats_reserved(event: SeatsReserved) -> None:
async for session in get_session():
booking = await _get_booking(session, event.booking_ref)
if booking and booking.status == BookingStatus.SEATS_RESERVING:
booking.status = BookingStatus.PAYMENT_AUTHORISING
That if booking.status == BookingStatus.SEATS_RESERVING check is doing two things. First, it prevents processing stale events. Second, it acts as an implicit guard - if the booking is already past this step, the event is ignored. This makes the handler naturally idempotent.
When payment succeeds, same pattern:
@broker.on_event(PaymentAuthorised)
async def on_payment_authorised(event: PaymentAuthorised) -> None:
async for session in get_session():
booking = await _get_booking(session, event.booking_ref)
if booking and booking.status == BookingStatus.PAYMENT_AUTHORISING:
booking.status = BookingStatus.CHECKIN_ALLOCATING
The orchestrator is boring on purpose. It’s a router: event comes in, state advances, next service reacts. The interesting engineering lives in what happens when something goes wrong.
When Things Go Wrong #
Happy path is easy. Let’s break it.
Payment gets declined. At this point, seats are already reserved - they’re locked in the inventory service’s database. We can’t reach into that database and undo the reservation. What we can do is publish an event that tells the inventory service to release them.
This is a compensating transaction. Not a rollback - a new forward action that semantically undoes the effect of a previous step.
The compensation map #
Each forward step has a corresponding compensation:
| Forward Action | Compensation |
|---|---|
| Seats reserved | Release seats |
| Payment authorized | Void payment |
| Check-in allocated | Cancel check-in |
Miles are the terminal step - if the booking was confirmed and miles were awarded, we don’t revoke them on failure. That’s a business decision, not a technical one.
Reverse order matters #
When payment fails, only seats need to be released. When check-in fails, both the payment and the seats need to be unwound - and in that order. You void the payment before releasing the seats, because releasing seats while the card is still charged is a worse inconsistency than the reverse.
Here’s the compensation logic (full source):
COMPENSATION_EVENTS = {
SagaStep.CHECKIN: CancelCheckin,
SagaStep.PAYMENT: VoidPayment,
SagaStep.SEATS: ReleaseSeats,
}
async def run_compensation(
broker: Broker,
booking_ref: str,
last_successful_step: SagaStep,
) -> None:
for step in range(last_successful_step, SagaStep.SEATS - 1, -1):
saga_step = SagaStep(step)
if saga_step in COMPENSATION_EVENTS:
event_class = COMPENSATION_EVENTS[saga_step]
event = event_class(booking_ref=booking_ref)
await broker.publish("saga:compensations", event)
await asyncio.sleep(0.1) # artificial delay for dashboard visibility
rollback_event = SagaRolledBack(
booking_ref=booking_ref,
failed_at_step=SagaStep(last_successful_step + 1).name_lower,
)
await broker.publish("saga:events", rollback_event)
The SagaStep enum is an IntEnum ordered by execution sequence. The loop walks backwards from the last successful step down to SEATS, publishing compensation events.
Triggering compensation #
When a failure event arrives, the orchestrator kicks off the compensation chain:
@broker.on_event(PaymentDeclined)
async def on_payment_declined(event: PaymentDeclined) -> None:
updated = False
async for session in get_session():
booking = await _get_booking(session, event.booking_ref)
if booking and booking.status == BookingStatus.PAYMENT_AUTHORISING:
booking.status = BookingStatus.COMPENSATING
booking.failed_at_step = SagaStep.PAYMENT.name_lower
updated = True
if updated:
asyncio.create_task(
run_compensation(get_broker(), event.booking_ref, last_successful_step=SagaStep.SEATS)
)
The booking moves to COMPENSATING state, records where it failed, and fires off the compensation as a background task. Once all compensations complete, a SagaRolledBack event arrives and the booking transitions to CANCELLED.
The key insight: compensation is business logic, not infrastructure magic. Voiding a payment isn’t the same as never charging the card - there’s an audit trail, possibly a notification to the customer, maybe a hold period. Releasing seats makes them available for other bookings immediately. These are real operations with their own semantics and their own failure modes.
The Dual-Write Trap #
There’s a subtle problem hiding in the inventory service. When a booking comes in, the service needs to do two things:
- Reserve the seats in its database
- Publish a
SeatsReservedevent to Redis
What happens if the database commit succeeds but the Redis publish fails? The seats are locked, but the saga never advances. The orchestrator is waiting for an event that will never arrive. The booking is stuck forever in SEATS_RESERVING.
This is the dual-write problem. You need to update two systems atomically, but there’s no transaction that spans both.
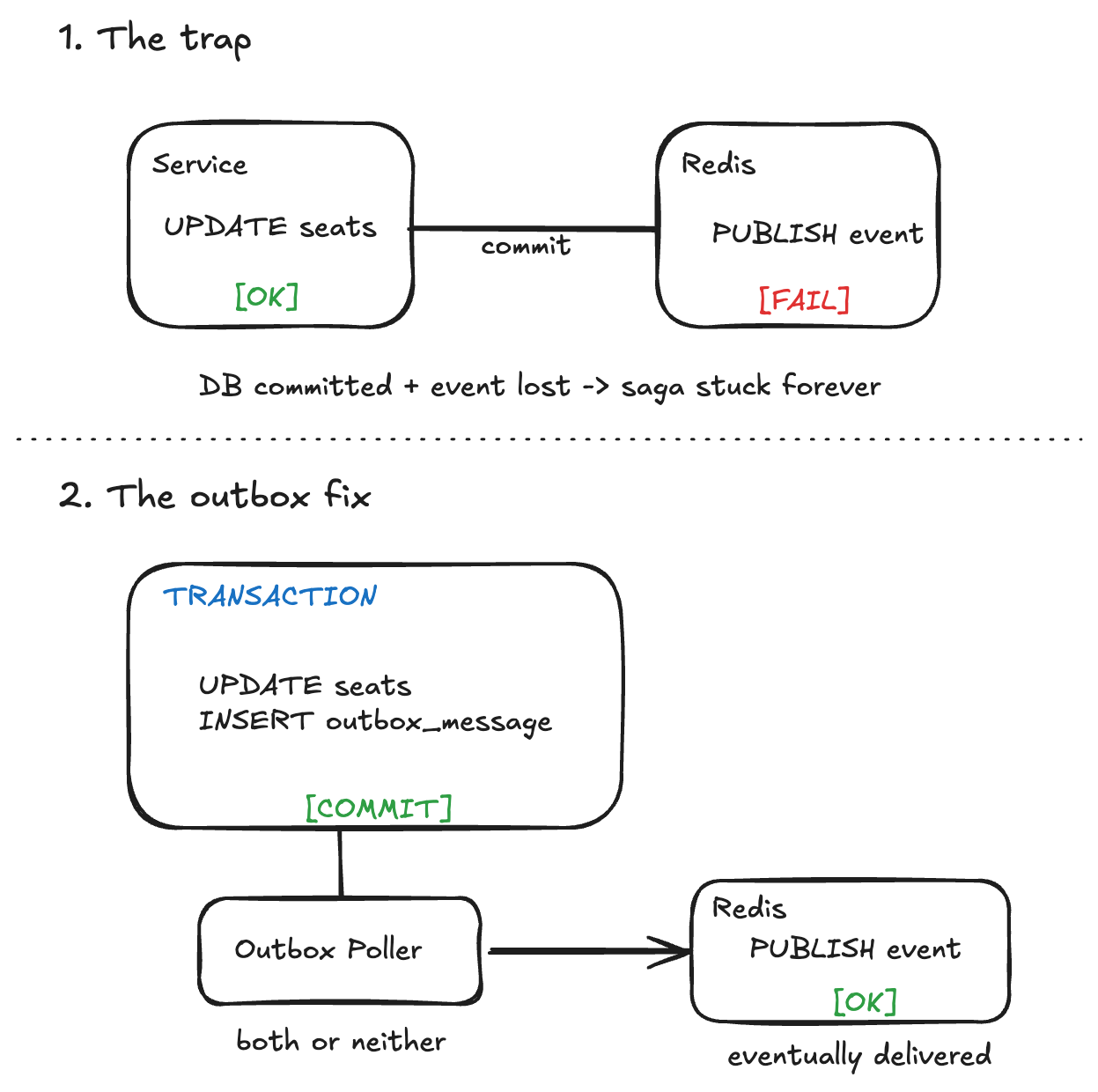
The wrong approach #
# Don't do this
seat.status = SeatStatus.RESERVED
await session.commit() # succeeds
await broker.publish(event) # fails - event lost, saga stuck
The outbox pattern #
The solution: don’t publish directly. Write the event to an outbox table in the same database transaction as the data change. A background process reads the outbox and publishes to Redis.
# Reserve seats and write to outbox in one transaction
seat.status = SeatStatus.RESERVED
seat.booking_ref = booking_ref
outbox_message = OutboxMessage(
channel="saga:events",
payload=seats_reserved.model_dump_json(),
)
session.add(outbox_message)
await session.commit() # Both or neither
The seat reservation and the outbox message are in the same database transaction. If either fails, both roll back. No inconsistency possible.
Then a background poller picks up unpublished messages:
class OutboxProcessor:
async def _process_pending_messages(self, engine) -> None:
async with AsyncSession(engine) as session:
result = await session.execute(
select(OutboxMessage)
.where(OutboxMessage.published_at.is_(None))
.order_by(OutboxMessage.id)
.limit(100)
)
messages = result.scalars().all()
for message in messages:
await self.broker._redis.publish(message.channel, message.payload)
await session.execute(
update(OutboxMessage)
.where(OutboxMessage.id == message.id)
.values(published_at=datetime.now(timezone.utc))
)
await session.commit()
The poller runs every 500ms. It reads unpublished messages, publishes them to Redis, and marks them as published. If publishing fails, the message stays in the outbox and gets retried on the next poll.
This means events might be delivered more than once - the publish could succeed but the “mark as published” commit could fail. That’s fine, because the handlers are idempotent. Processing the same event twice produces the same result.
Why this matters for sagas #
A lost event in a saga isn’t just a missed notification - it’s a permanently stuck transaction. The orchestrator will wait forever for a reply that never comes. No timeout will save you cleanly, because you don’t know whether the service processed the request and failed to publish, or never received it at all.
The outbox pattern makes event publishing as reliable as the database itself. If the data was written, the event will eventually be published.
Seeing It Live #
All of this is running in the companion repository. Five services, Redis pub/sub, Postgres, and a real-time dashboard that shows saga state transitions as they happen.
make up && make seed
open http://dashboard.localhost
The seed script fires seven bookings - some configured to succeed, others to fail at different stages. The dashboard connects to an SSE stream from the booking service and renders each saga’s progress through its steps.
Set PAYMENT_FAIL_RATE=0.5 in your .env and watch roughly half of all bookings trigger compensation cascades. Set it to 1.0 and every booking fails at payment - you’ll see ReleaseSeats fire for each one.
The dashboard isn’t the point of this project, but it makes the pattern tangible in a way that logs and database queries never will. Watching a saga roll back in real time - step by step, in reverse order, with visible delays between compensations - builds intuition that reading about the pattern never quite delivers.
What This Doesn’t Do #
This is a learning resource, not a production blueprint. Some deliberate shortcuts:
- No dead-letter queue. If a handler throws repeatedly, the event is lost. Production systems need a DLQ and alerting.
- Redis pub/sub has no persistence. If a subscriber is down when an event fires, that event is gone. Production: Redis Streams or Kafka.
- No timeouts. A stuck saga stays stuck. Production systems need saga deadlines and escalation.
- No structured logging, no auth, no proper service isolation. Services query each other’s schemas directly instead of staying truly independent.
If you borrow patterns from this project, treat each of these as a known gap to close before shipping.
The core ideas - state machine orchestration, reverse-order compensation, transactional outbox - those transfer directly. The infrastructure around them is where production engineering begins.
Sagas don’t eliminate failure. They make failure a first-class part of the design. That shift matters more than the code.